AI 时代,重识羊驼
https://sspai.com/post/79443
本文首发于少数派:https://sspai.com/post/79443,感谢编辑校核,此处为原始版本
引言
2008 年,北京奥运会举世瞩目,五福娃吉祥物风靡一时。除象征奥林匹克圣火的红色欢欢外,其余四者均以动物为原型——蓝色的鲤鱼贝贝、黑色的熊猫晶晶、黄色的藏羚羊迎迎、绿色的京燕妮妮,动物们饱含东方元素,富于奥运精神,吉祥喜人。

次年初,贴吧惊现「草泥马」,随即在聊天室、论坛等处广为流传。作为「草泥马」形象的取源,本分布于南美洲的羊驼开始为东亚民众所知,其形似绵羊的皮毛下,有着驴马混搭的身形和滑稽的面部,加上心情不好便喷口水的习惯,深得网友喜爱。于是很快地,这个物种顶着新名字席卷中文互联网,在各处充当别有新意的「吉祥物」,风头一时无两。

不过少有人知的是,很长一段时间里,羊驼给物种分类提出了一定挑战。
碳基羊驼
虽有俗名「草泥马」,但羊驼并非一种马,如种名羊驼所示,其大意为长相似羊的一种驼。驼,即是骆驼,与羊驼在面部确有几分相似,只是背部多了耸起的峰。可想而知,相比于羊,羊驼与骆驼在分类上是更相近的种族。事实上,它们同归骆驼科下,分属骆驼族与美洲驼族。
分类一览
如果从骆驼亚科(为骆驼科现存唯一亚科)看起,其科内族属关系如下:
- 骆驼族:下仅有骆驼属一个属,骆驼属内有双峰驼、野生双峰驼和单峰驼;
- 美洲驼族
- 羊驼属,也叫骆马属
- 大羊驼(Llama):有时称美洲驼,也叫拉马,偶称骆马
- 原驼(Guanaco):也称野生羊驼
- 小羊驼属
- 羊驼(Alpaca):俗名「草泥马」
- 小羊驼(Vicuna):也叫骆马

不难察觉,整个美洲驼族中两属四种的名字与称呼,主要突出一个「乱」字。由于中文译名的原因,美洲驼、羊驼、骆马等称呼在不同的语境中可能指代整个族、某一属、个别种,在种间也多有混用。本文以前述族属关系中的粗体命名为准。
逐一相认
与咖啡杯量的划分雷同,大羊驼和羊驼分别属于羊驼属和小羊驼属。区别于野生的原驼与小羊驼,大羊驼和羊驼为驯化物种,而且是新大陆被发现之前南美洲仅有的驯化牲畜。
大羊驼是美洲驼族当之无愧的大哥,身高与成年男子相仿,体重约为人两倍,耳朵多呈稍有弧度的香蕉状,擅长驮负重物,也是驯养主要功能。
羊驼,即我们熟悉的「草泥马」,身形稍小,头高如同小学生,体重则接近成人,有尖尖的直耳,皮毛具有不错的经济价值。
野生的原驼和小羊驼,则分别比其同属的驯养种小一号,身形也更为苗条:原驼高 1 米出头,重百公斤;小羊驼高约 80 公分,重 50 公斤上下。均为直耳,皮毛不如驯养的羊驼丰满,多有更出色的运动能力。
除了名字混乱之外,其各种间杂交带来的基因置换则更为难辨。比如,羊驼与大羊驼应算是表亲。实际上,在 2001 年根据基因研究结果改正之前,羊驼都还属于羊驼属,后来发现羊驼与野生的小羊驼在血缘上更为接近,遂移至小羊驼属。这也不能怪一开始分类不准确,毕竟西班牙人刚殖民南美时,也根本没分清大羊驼和羊驼,都是混在一起养,于是大羊驼给了羊驼 36% 的 DNA,羊驼再回赠 5%,这才导致了羊驼被分到了表亲大羊驼所在的羊驼属[^1]。
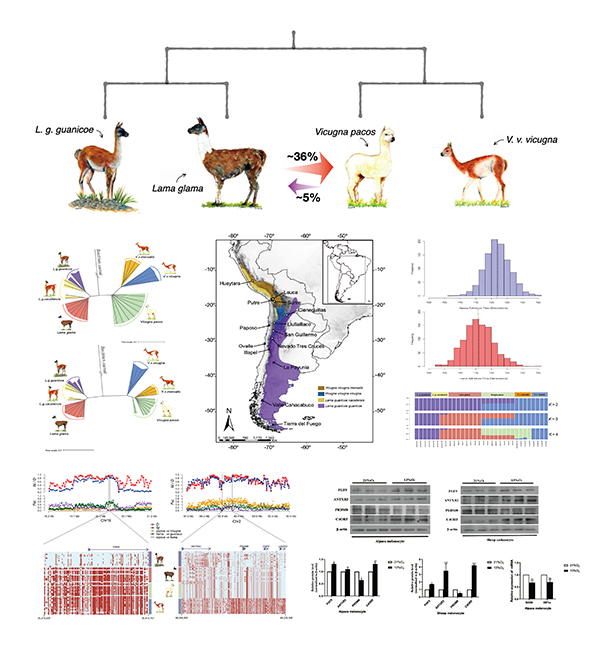
至此,「大中小原」四种美洲驼已基本理清。
硅基羊驼
转眼进入 AI 时代,ChatGPT 吹起了一股大语言模型之风,恐怕羊驼们绝不曾想到,自己的种族竟也被卷入其中。
命名这件小事
尽管 ChatGPT 热度陡升之后,周边项目呈现出疯狂抢占 ChatXXX 与 XxxGPT 名号的潮流,但源头处,OpenAI 官方在为 GPT(Generative Pre-trained Transformers)家族命名时,还是以朴实无华为主。除了 GPT-1/2/3/3.5/4 的数字系列,在预训练模型上进行指令精调的 InstructGPT、为对话场景加入人类反馈强化训练的 ChatGPT,都拘谨又直观地表明了模型的核心及侧重。因此,当其名为 Whisper 的语音识别模型发布时,有人挠破头皮也想不出来这种巧妙的缩写从何得来,直到在论文中发现一条不起眼的脚注[^2]——欲寻缩写词源,可用 WSPSR 凑合一下:
If an acronym or basis for the name is desired, WSPSR standing for Web-scale Supervised Pretraining for Speech Recognition can be used.
至于 DALL-E 这个即致敬艺术家(Salvador Dalí)[^3]又碰瓷机器人(WALL-E)[^4]、根本没个缩写来源的产品式命名,便更不要提了。

众所周知,ChatGPT 虽开放免费试用并提供 API 供开发者调用,但并未公开模型细节,又因其效果遥遥领先,引发关于「AI 垄断」的声讨亦此起彼伏。追赶者中,Google 依赖扎实的研究团队,在 CEO 紧盯下闭门造车;Meta 则选择了另一条路,将预训练的底座模型释放出来,希望调用社区力量阻击。
羊驼再次登场
2023 年 2 月 24 日,Meta AI 发布预训练大语言基础模型[^5]:LLaMA(Large Language Model Meta AI)[^6]。基于 1.4 万亿语料(token)预训练的 LLaMA 65B 具有 650 亿参数量,同系列还有 33B、13B、7B 不同参数量的版本(后两者训练语料略少些)。作为对比,ChatGPT 的底座模型 GPT-3 175B(代号 davinci )参数量为 1750 亿。故仅从参量而言,大羊驼仍显著逊色于「达芬奇」。
值得注意的是,Meta 特别说明 LLaMA 是以非商业授权的形式发布,应主要用于学术研究。其 GitHub 仓库仅给出加载运行模型的示意代码,若要获取核心模型权重,还需要填写表单申请。尽管如此,释出的模型无疑给久旱的社区注以甘霖,为挑战 OpenAI 封闭式炼丹吹响冲锋的号角。
事实上,接下来的短短数十天内,在大羊驼 LLaMA 的托举下,羊驼们已然蓬勃成军,正朝看似高不可攀的 ChatGPT,全方位、一步步地追赶进攻——
- 3 月 13 日,斯坦福大学基础模型研究中心(Center for Research on Foundation Models,CRFM)发布了指令精调模型 Alpaca 7B[^7],使用 5.2 万由 OpenAI 的
text-davinci-003模型[^8]生成的指令数据,对 LLaMA 7B 进行精调而得。斯坦福羊驼横空出世,开源了包括准备过程、数据集、训练步骤等在内的整套方案,经评估能取得近似text-davinci-003的指令服从效果,但低成本且高效、易于复现,经验启发了许多蠢蠢欲动的后来者;
- 3 月 16 日,在 Alpaca 基础上补充了多语种语料和指令任务的 Guanaco 原驼模型问世[^9];
- 3 月 19 日,来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣地亚哥分校的几位计算机博士组队,以大模型系统(Systems for Large Models,LM-SYS)的名义发布了 Vicuna-13B[^10],基于 ShareGPT 收集的对话对 LLaMA 进行精调,仅需 300 美元即完成训练的小羊驼,号称达到了 ChatGPT 90% 的能力,并将 Meta 大羊驼和斯坦福羊驼均甩在身后;
- 3 月 23 日,Chinese-Vicuna 中文小羊驼携模型及数据面世,基于 LLaMA 模型和 LoRA 方案,可按需投喂数据进行个性化指令精调;
- 3 月 24 日,Databricks 发布 Dolly 模型[^11],基于「有些过时」的 GPT-J-6B 精调,证明精调指令数据比底座模型更为重要,考虑到其本质是 Alpaca 的开源克隆[^12],故取克隆羊多利之名;
- 3 月 25 日,来自华中师范大学和商汤的几位伙伴发布了中文骆驼模型[^13],坦白命名逻辑:
我们将项目命名为 骆驼 Luotuo (Camel) 主要是因为,Meta之前的项目LLaMA(驼马)和斯坦福之前的项目alpaca(羊驼)都属于偶蹄目-骆驼科(Artiodactyla-Camelidae)。而且骆驼科只有三个属,再不起这名字就来不及了。
- 3 月 28 日,中文 LLaMA & Alpaca 大模型发布,在 LLaMA 基础上扩充了中文词表并加入中文数据预训练,以及与 Alpaca 相似但增加了中文指令数据的精调,显著提高模型中文能力;
- 日新月异,不堪尽数……

不止模型,周边配套工具同样呈星火燎原之势:大幅降低推理成本的 llama.cpp、连接羊驼与外部资料的 LlamaIndex、对羊驼模型进行局部再训练的 Alpaca-LoRA、训练提高羊驼感知链的 Alpaca-CoT、在 macOS 优雅地跟羊驼们聊天的 LlamaChat ……全链条覆盖,俨然已自成生态。只等某天时机成熟,便围攻 OpenAI 于光明顶。
结语
据说羊驼母亲妊娠时间长达 11.5 个月,但刚分娩出世的羊驼仔落地即可奔跑。这与 LLaMA 和 Alpaca 发起的大语言模型平民化运动莫名雷同——起步虽晚,加速极强。
时至今日,美洲驼一族已不局限于南美,其凭借惹人喜欢的外表和聪明友善的性格,正被全世界人民了解。另一边,大语言模型发展仍纷繁暇目,羊驼伙伴名字都几乎用尽,转而以一种精神符号存活于开源社区的各处,激励大家继续求索。希望在不久的将来,AI 人人可用。
本文是笔者在追踪 LLM 社区发展过程中的一些片段记录,出自好奇,收获有趣,与君分享。
参考
- 动物所等揭示羊驼和美洲驼驯化起源机制,中科院之声
- 西班牙超现实主义画家萨尔瓦多·达利
- 皮克斯动画《机器人总动员》中的形象瓦利
- Meta 在命名时同样喜欢图吉利凑个整,比如在部分开源项目中还广泛存在的 FAIR(Facebook AI Research)印记,此处官方并无明确缩写词源,仅根据推测标粗
- Alpaca: A Strong, Replicable Instruction-Following Model,Stanford CRFM
text-davinci-003是 OpenAI API 中的模型名,与 ChatGPT 对应的gpt-3.5-turbo同属 GPT-3.5 系列,后者在前者基础上有提升,特别针对对话场景优化
- Dolly v1 虽不涉及 LLaMA 许可,但因 Alpaca 所用指令精调数据通过调用 OpenAI API 生成,按照 OpenAI 的非竞争条款不可商用;于是 Databricks 发动公司员工举办了标注竞赛,所得数据精调来的 Dolly v2 终于可以商用
- 本文封面即引自该项目的放克羊驼